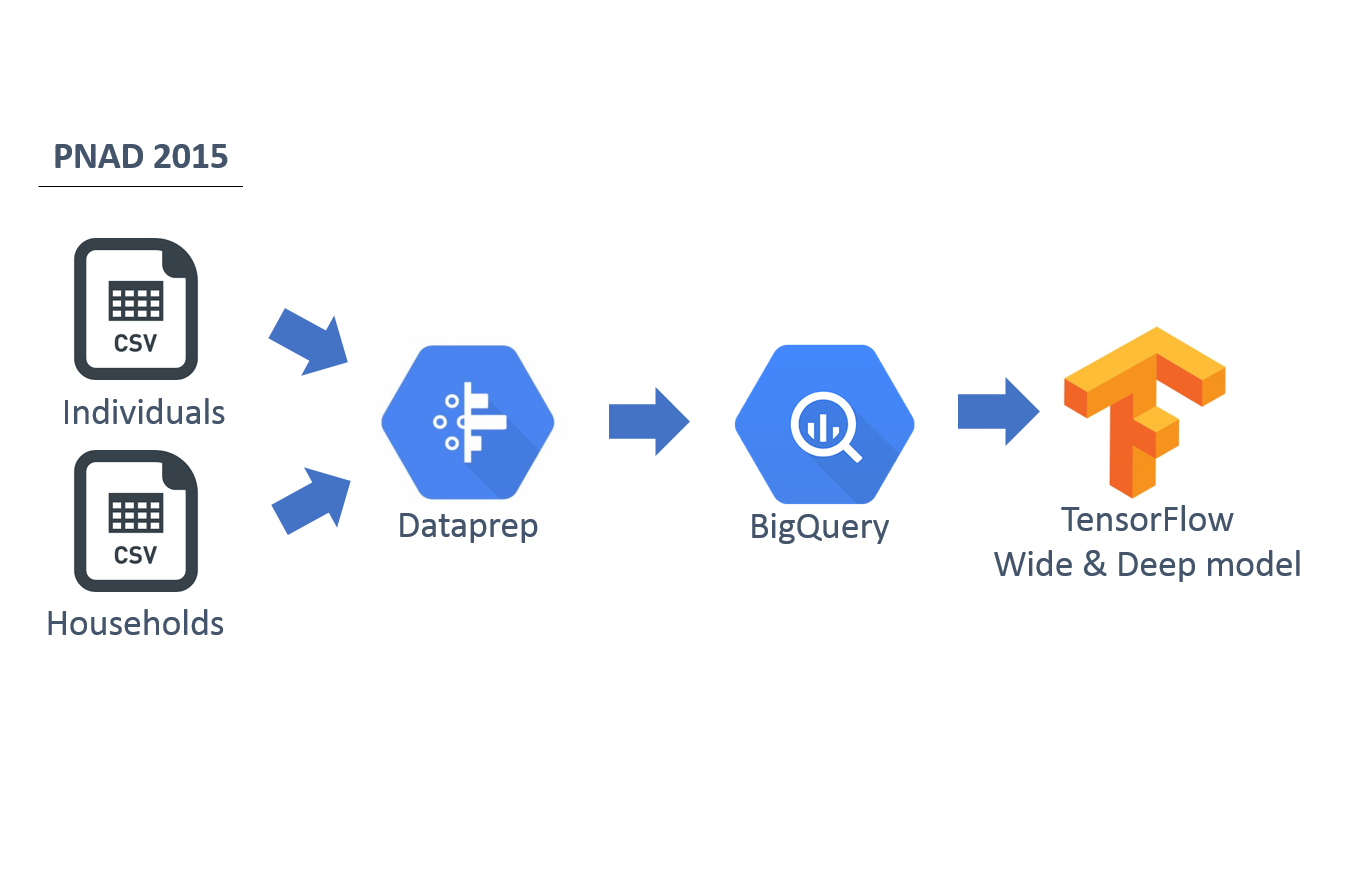
We started this study with the CSV files(1) from PNAD survey related to individuals and to households. Initial data cleaning was done using Dataprep on Google Cloud Platform. The data from the two files were loaded to two tables at BigQuery.
Then we used a Join query on the household identifier to connect the data of individuals to the data of the households, where they live. This query was materialized into a new table with all the information. We got the consolidate data from BigQuery to a Jupyter Notebook running Python 3, where we produce our model. The figure below depicts the flow of data.

Sampling the data to avoid data leaking
When we separated the train, validation and test datasets from the whole database, we took the precaution to control that each subset of the original dataset to include data from different families. The household data of individuals from the same family is repeated and we have to make sure that we are not testing with the same data used in the training. Therefore, the household index was used to separate the household data across the datasets.
Handling imbalanced datasets with undersampling
An issue for the binary classification is when in the available data one class naturally predominates over the other. This is the case when we set the income level boundary at BRL 6,585 per month; only 10% of the families have this income.
When such imbalance happens the machine learning models tend to predict the predominant class in order to maximize accuracy. In order to avoid that, we used an undersampling technique (more details can be found here). In the training dataset we kept all individuals with income greater than BRL 6,585 and sampled approximately 12% of the lower income individuals, making the resulting sample balanced in class distribution, although with less data points. The chart below illustrates that process.

Tensorflow Wide & Deep Model
We applied a Tensorflow Wide & Deep Model inspired in the Wide&Deep model presented in Tensorflow tutorial using the 1994 US Census Income Dataset. This type of model combines the strengths of memorization from the wide part (logistic regression) and generalization from a deep neural network.

In the wide part we used crossed columns combining features related to household location, age of individual, professional occupation, education and goods presented in the household. The neural network had only two hidden layers, with 200 and 50 nodes. We trained the model with 20,000 steps with batch size of 500 examples, achieving an accuracy of approximately 85%. Below the average loss curve, decaying with the training process.

The details of the model and its code in Python can be found in the following GitHub.
References: (1) We got the CSV files from Vitor George public GitHub (April, 2018)

