In many business situations is important to identify the level of income of an individual. For example, when planning a marketing campaign it might be an important information for customer base segmentation. In banking it is fundamental for credit approval.
However, income information might be hard to obtain. Customers might be reluctant of disclosing this information. On the other hand, some customers might be willing to disclose it, when requiring a loan for instance. In this case income information might be inflated. Therefore, it is useful to estimate the customer income level, without using the income information itself. In the case of credit, an estimate could be used to confirm the if the income data informed by customer is plausible. If not confirmed, in the case that the estimate is significantly lower than the informed income, a bank could initiate a specific process to double check it, such as requiring additional formal documentation on wage, employment, etc.
We created a model to estimate income brackets using the demographic data in PNAD survey from IBGE, which researches information about the Brazilian population. This survey has data both households and individuals. We prepared a specific study on Brazilian income distribution using PNAD that can be found here.
Building a model to assess customer income
Our model is inspired in the Wide&Deep model presented in Tensorflow tutorial using the 1994 US Census Income Dataset. In our case we are using 2015 PNAD survey, and applying a family income of BRL 6,585 per month to define ranges. We used family instead of individuals just to match the social-classes criteria, since BRL 6,585 is the boundary that separates classes A and B from C, D and E. It would have been also possible to use individual income or family income per-capita as well. Depending on the business application, different metrics might be more convenient. Like the Tensorflow tutorial model, we are using only information from adult individuals, people with age greater or equal to 18 years old.
The information selected from PNAD is showed in the below group by type of variable:

We were careful to not use some information that would not be available, problematic to get, or even illegal to ask in a real business scenario such as race or census area.
We also simplified the “type of location” feature, with had 8 possible values such as “urban – city or town, not urbanized area” or “urban – isolated urban area”. These definitions could be meaningful to the IBGE researchers but difficult to be assimilated by layman. Therefore, we reduced the 8 types of location categories to only 2: “urban” and “rural”.
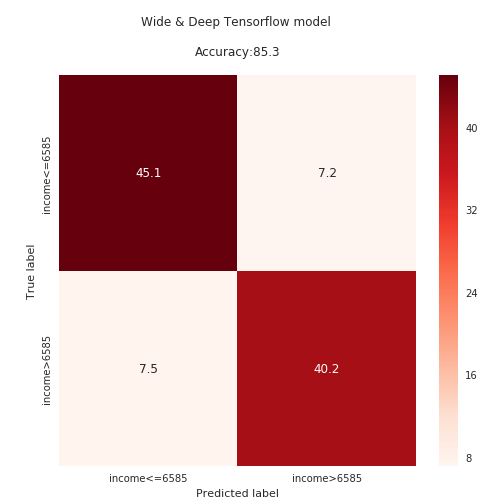
The performance was evaluated using a validation sample where both classes where balanced and a test sample with distribution similar to the original PNAD dataset (i.e. imbalanced towards low-income class). In both samples we achieve accuracies of approximately 85%, as shown below:

In this validation test we checked the model perfomance for nearly 4,600 individuals, of which 52.3% were from families with monthly income less or equal to 6,585 and 47.7% from families with income superior to that limit. We see that model classified correctly 85.3% of the cases.
Evaluating the income of individuals, who not declared income
In PNAD survey, 1.9% of adult individuals do not declared monthly family income as showed in the chart below. We would like to evaluate what would be the income range of these people, if lower or greater than BRL 6,585 per month.

So we run the model for these 5,383 cases of not declared income, and we got the distribution below, which is very different from the rest of the database.

The results indicate that high income individuals are less keen on disclosing their income information.
