
Go direct to the Summarizer App for demostration
Contents
- Introduction
- Model architecture
- Data processing
- Training the Model
- Model results and comparison with the extractive approach
- Model serving on the cloud
1. Introduction
This is the second part of my Capstone Project on Springboard ML Bootcamp using CNN stories dataset to produce text summaries. In this part of the project, we will use an abstractive approach, which is to generate a complete new text from the “comprehension” of an article, applying Machine Learning.
The details of the CNN dataset as well as the insights from the Exploratory Data Analysis can be found in the previous article, Text Summarization Part 1: Using extractive approach to create summaries.
2. Model Architecture
The model was based on a sequence-to-sequence Recurrent Neural Network architecture, including an Attention Mechanism, using Luong algorithm. The encoder and decoder parts of the model are made of steps handling one token from the text, which can be a word or punctuation signal. Each RNN step is comprised by 256 LSTM (Long Short-Term Memory) cells, forming only one layer. The encoder is bi-directional with 400 steps and the decoder is unidirectional with 80 steps. A chart on the model architecture can be seen in the figure below:
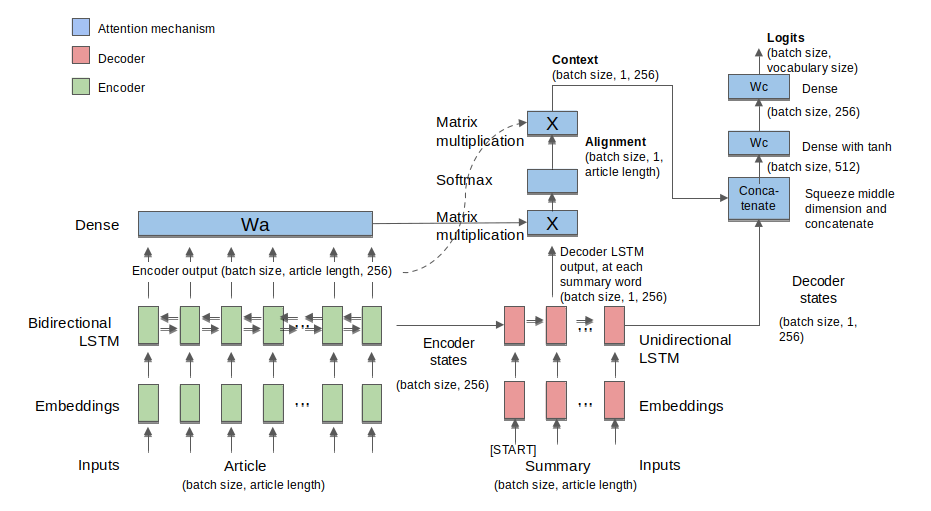
The model was implemented using TensorFlow 2.0, which has the advantage of eager execution (no more session.run() calls) and coding the training, evaluation and prediction with shorter functions.
The model is fed with an embedding layer, representing the text tokens with 100-length word embeddings. This layer was pre-loaded with embeddings taken from GloVe-100 trained vectors, whose data can be downloaded from Standford University site. In training, we opted to let the embeddings layer trainable, so the vectors could be fine-tuned to the specific conditions of the training dataset.
3. Data Processing
In order to make the RNN seq-2-seq model run properly, it is necessary to preprocess the source text, converting it to lower case, replace English contractions by the full version of the corresponding expression, removing special characters, placing spaces before punctuation to separate them from words, among other transformations that are depicted on the chart below:
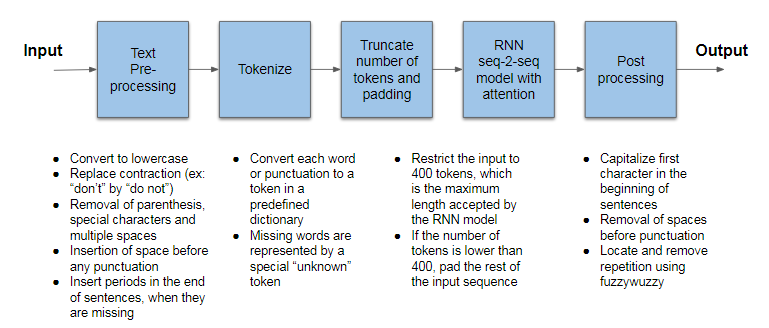
The text preprocessing is important to ensure that the source text can be more easily converted into tokens, which are numerical representations of each single word or punctuation from the original source text. Each word is searched in a predefined dictionary which was created during the training phase.
Another point to observe is that the encoder part of the RNN seq-2-seq model, in our deployed configuration, can only admit an upper limit of 400 tokens. This limitation was imposed due to the processing and memory burden of treating very long source texts. Therefore, if we desire to produce a summary from a longer text, we have to break it up in pieces of maximum 400 tokens in length and then join the resulting summaries. For source text pieces whose length is less than 400 tokens, we have to pad the remaining token positions.
Finally, there is a post process step on the resulting summary to make it more readable. This involves capitalizing the first letter of words in the beginning of sentences and removing the spaces before punctuation.
Moreover, to improve style we search for repetitive expressions and very similar sentences, in order to remove them. Summarization algorithms are prone to produce repetition and many practitioners treat within the model using cover mechanisms, for example. Here we used post processing methods using the fuzzywuzzy library for simplification.
4. Training the Model
Training the seq-2-seq model was the most challenging part of this project. The difficulties began in defining the best size of the encoder. Taking the CNN dataset, we were tempted to take 1,000 tokens of length size for the encoder, which would fit most of news articles entirely. But this revealed challenging in terms of training speed, memory and processing capacity. So, we limited the size to 400 tokens and selected approximately 20,000 articles short enough to fit the encoder.
Another issue, was the dictionary for tokenization. We started applying a model from a translation task, which used different dictionaries for the encoder and decoder. This is a common procedure when you have two different languages. However, for summarization we found out that this approach was not practical. Instead, we used an unique dictionary for both encoder and decoder.
An important step in tokenization is to ensure that the dictionary is not too big, which makes the processing of learning very difficult. So, in order to shorten the dictionary, we inspected the most common words in the corpus and only included those that showed up more than 5 times. This led to a loss of only 1.35% of total words in the corpus, but reduced by a factor of more than 3 the size of the dictionary. Missing words are represented by a special token “UNK”, and when they are not abundant they do not affect significantly the resulting summary.
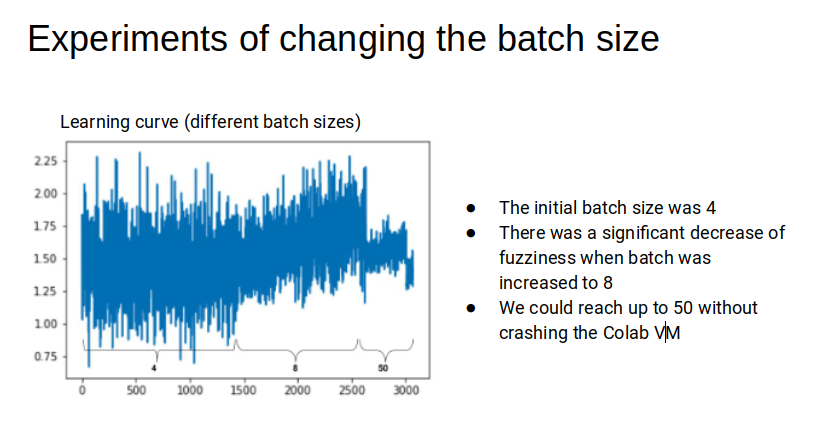
We also had a hard time finding the best batch size for the model. Small batches produced very fuzzy, hairy learning curves, so we increase the size of batches to increase stability of the curve. However, we hit an upper limit of 64 training examples, that could fit our GPU memory. The figure below illustrate some experiments with different batch sizes:
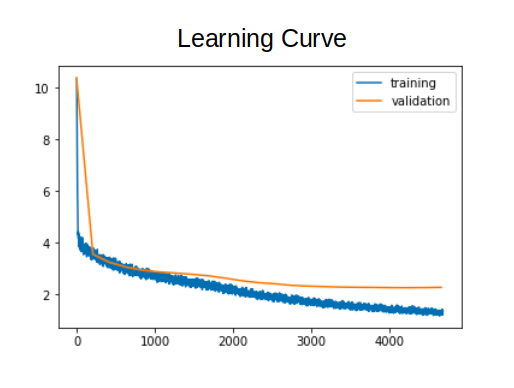
After many try and error attempts, and a lot of fine-tuning we could run a a smoother training process with a more stable learning curve like the one showed below:
5. Model results and comparison with the extractive approach
The chart below depicts a comparison of ROUGE scores between the extractive and abstractive approaches applied to 2,000 test articles, which were not used in the training of the model. All selected test articles were chosen to have 400 tokens to fit the abstractive model encoder size.
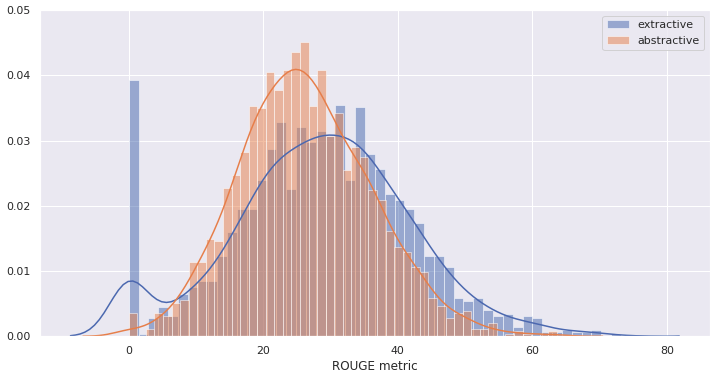
We can see that the extractive curve end up with a higher mean score of 28.5 vs. 26.3 for the abstractive curve. However, the dispersion of the extractive approach is also higher, with a standard deviation of 13.4 vs 9.8, including a significant number of articles featuring a round zero ROUGE score.
When we compare specific examples of summaries, we see that the abstractive model sometimes “invent” new content, probably based on what was learned in the training dataset. The sentences are not grammarly perfect and sometimes do not make sense. Below we see the same example of an article about NASA that was used in the previous article on Part 1 of the project.
First the article:
NASA engineers will repair small cracks found on the space shuttle Discovery’s external fuel tank — a development that could further delay its launch. “The X-rays showed four additional small cracks on three stringers on the opposite side of the tank from Discovery, and managers elected to repair those cracks …” NASA said in a statement. The work is expected to take two to three days. Additional repairs may be needed, NASA said. The cracks on support beams called “stringers” showed up during the latest round of image scans that NASA has been conducting to determine when the shuttle can take off, the space agency said Thursday. The earliest possible launch date is February 3, according to the agency. Earlier cracks found in the foam covering the fuel tank have repeatedly delayed the shuttle’s final launch, originally scheduled for November 1. Technicians repaired the cracks and reapplied foam insulation on aluminum brackets on the tank in November. The foam cracked while the tank was being filled November 5 for the shuttle’s planned launch to the International Space Station. Discovery is scheduled to deliver a storage module, a science rig and spare parts to the orbiting facility. The delay means the final launch of Endeavour, which is also scheduled to be the last launch of the space shuttle program, is likely to be delayed until April 1, said Bill Gerstenmaier, associate administrator for space operations
Now the abstractive summary:
Nasa says it will repair small cracks on the space shuttle discovery. The reactor was scheduled for november 1. Nasa says the radioactivity was not visible. The reactor will be completed until april 1
Therefore, we conclude that although the abstractive approach is very interesting from the theoretical standpoint, in practical terms the extractive might be more accurate in summarization tasks. The extractive approach was tackled by the first part of our project.
6. Model serving on the cloud
Due to size and complexity of the model, we opted to run it on a cloud serveless infrastructure. We chose, GCP Cloud Functions service for this task. So the model can be called using a HTTP POST call, as described below:
HTTP POST calls to the API
Format of API call:
curl --data-binary @<filename> https://us-central1-data-engineering-gcp.cloudfunctions.net/summarizer
The response is a JSON in the following format:
{"prediction" : "The generated summary"}
You can access the app on a web interface hosted on a GCP instance using this link. We are using streamlit framework to present the model results.
The app has a self explanatory page, where one inputs the text to be summarized and which approach to use, extractive or abstractive. When the button “Submit” is pressed, the generated summary appears in the field on the bottom of the page.


